Software engineering teams have been working with data for decades. It is data in apps and services they build. There is a well-known multitier architecture for data-driven applications.
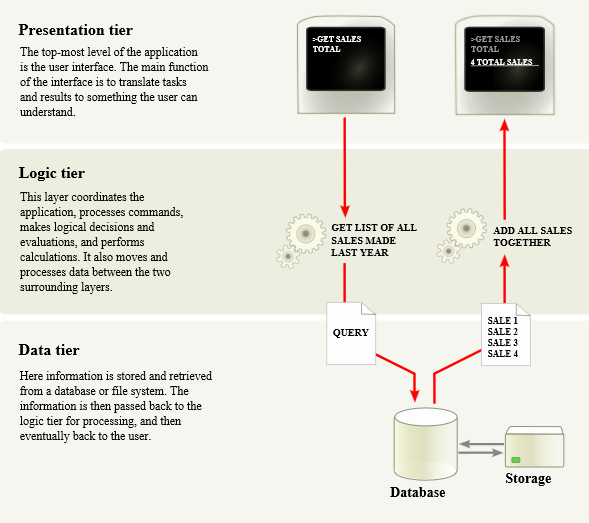
This is cool because it allows us to tune data schema for a specific domain, implement complex business logic and build slick user interface that will stand out among competition.
However the same approach applied to telemetry often leads to duplication and wasted effort. A shape of telemetry data does not change much from one app to another even across companies and industries. It aims to answer similar questions like how many times a feature is used, by how many users, how fast it is and if there are errors.
Borrowing and reusing is the key to build a robust telemetry system. Please do not write code to create yet another dashboard that shows telemetry data only for your application. It’s usually cheaper and more flexible to connect an existing data visualization solution like Excel directly to the data source.
While application data captures the current state of the world, telemetry data stores rich history of user interactions and application behavior. Expect telemetry data to be orders of magnitude larger than application data. Apps with small usage may get away with a standalone database for telemetry. Ambitious teams who expect rapid growth should plan for a big data storage that supports MapReduce to process terabytes of data in minutes.
An architecture of a telemetry system can be greatly simplified. The only custom code that should be required are queries to formulate business questions.
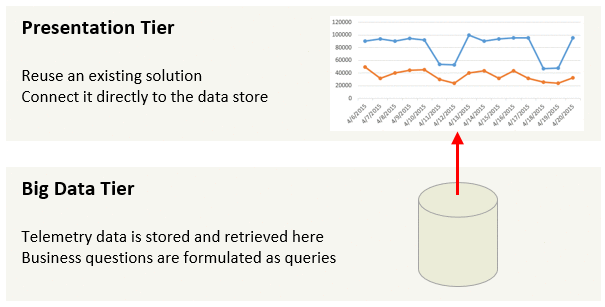
This approach can save weeks of engineering effort. Enjoy this time to make your app or service even better!

Pingback: Enabling software developers to complete the Build-Measure-Learn cycle | Data Driven Engineering for Software Developers
Pingback: All things data newsletter #10 (#dataengineer #datascience) | Insight Extractor - Blog